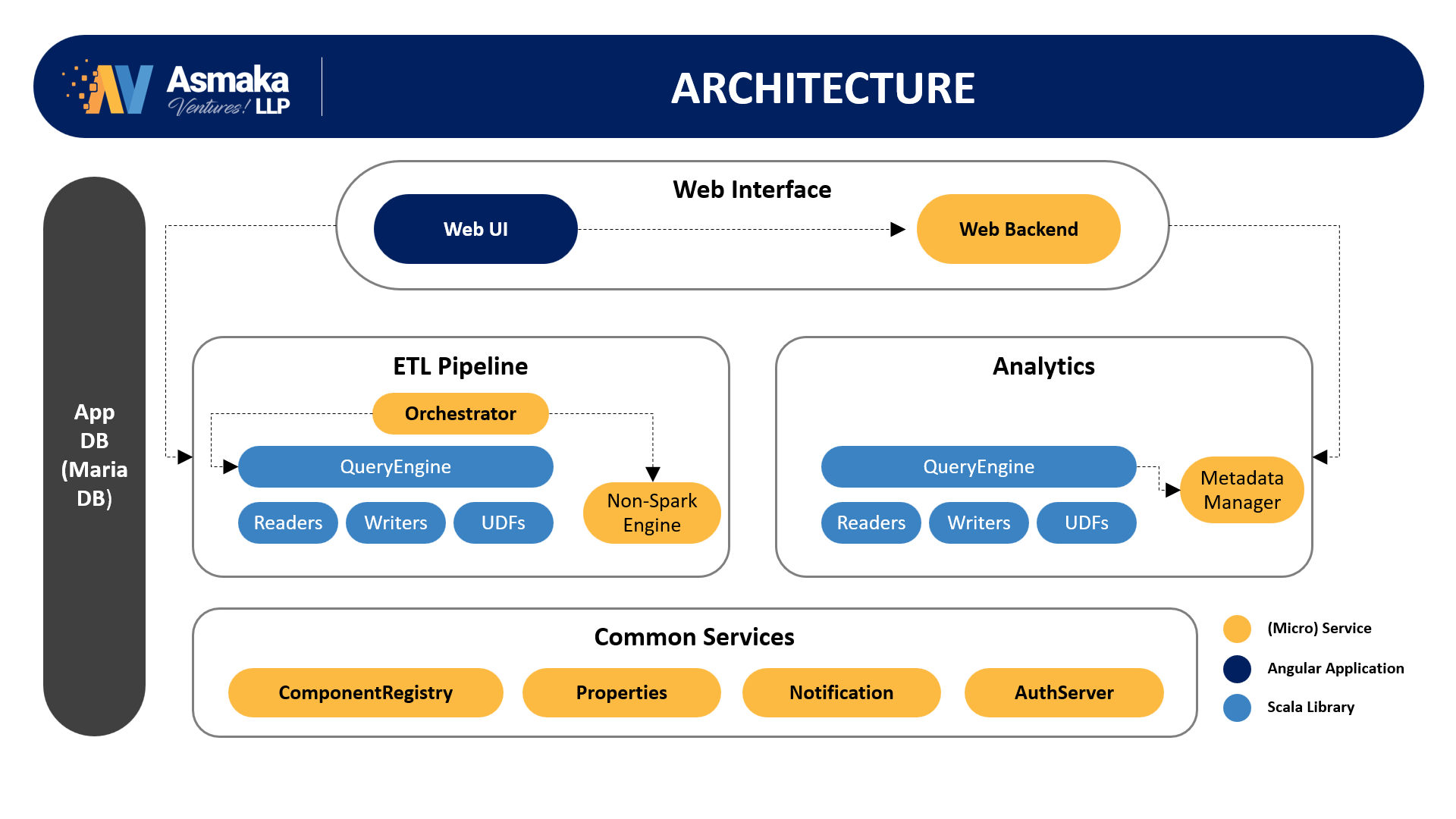
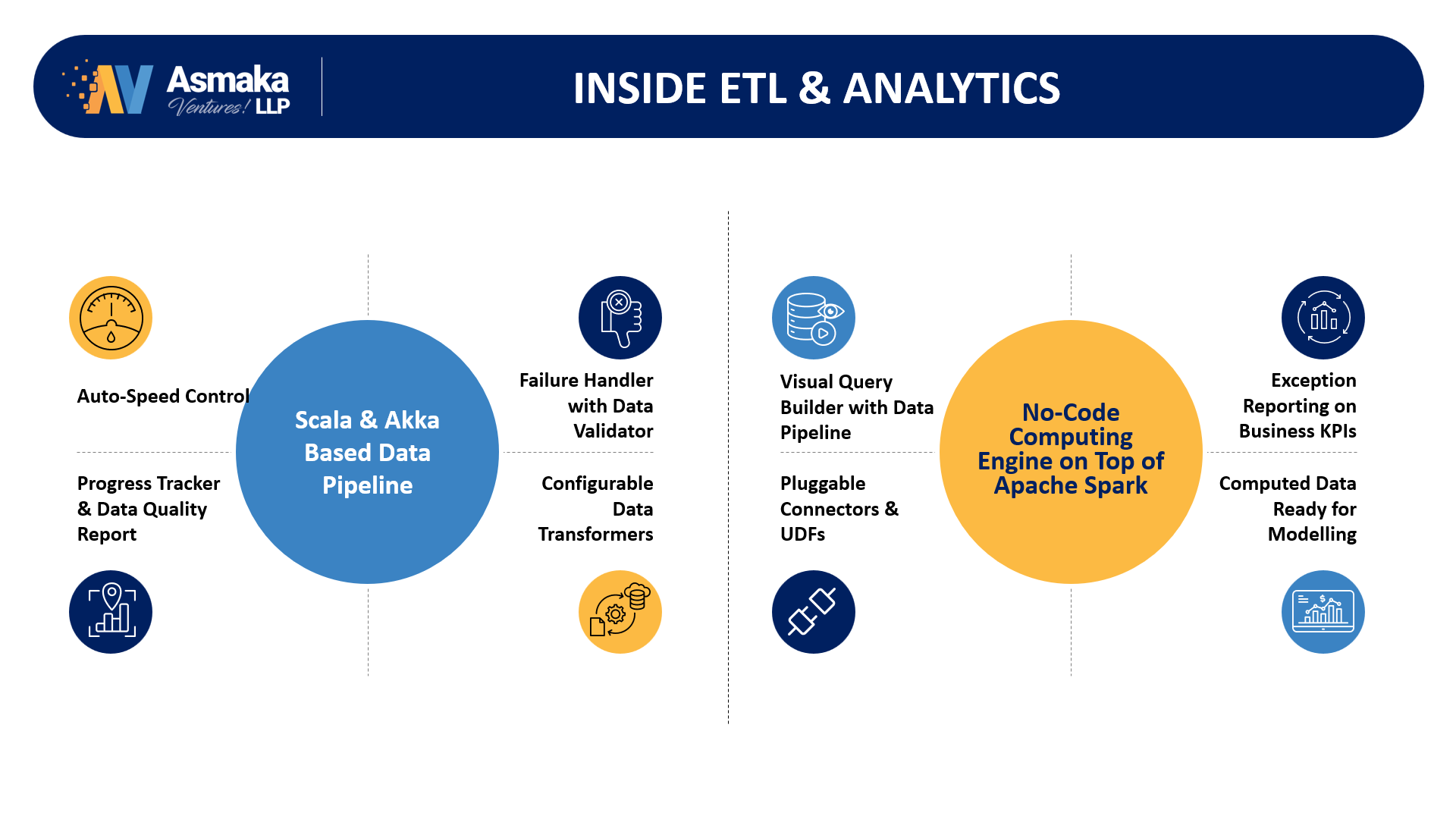
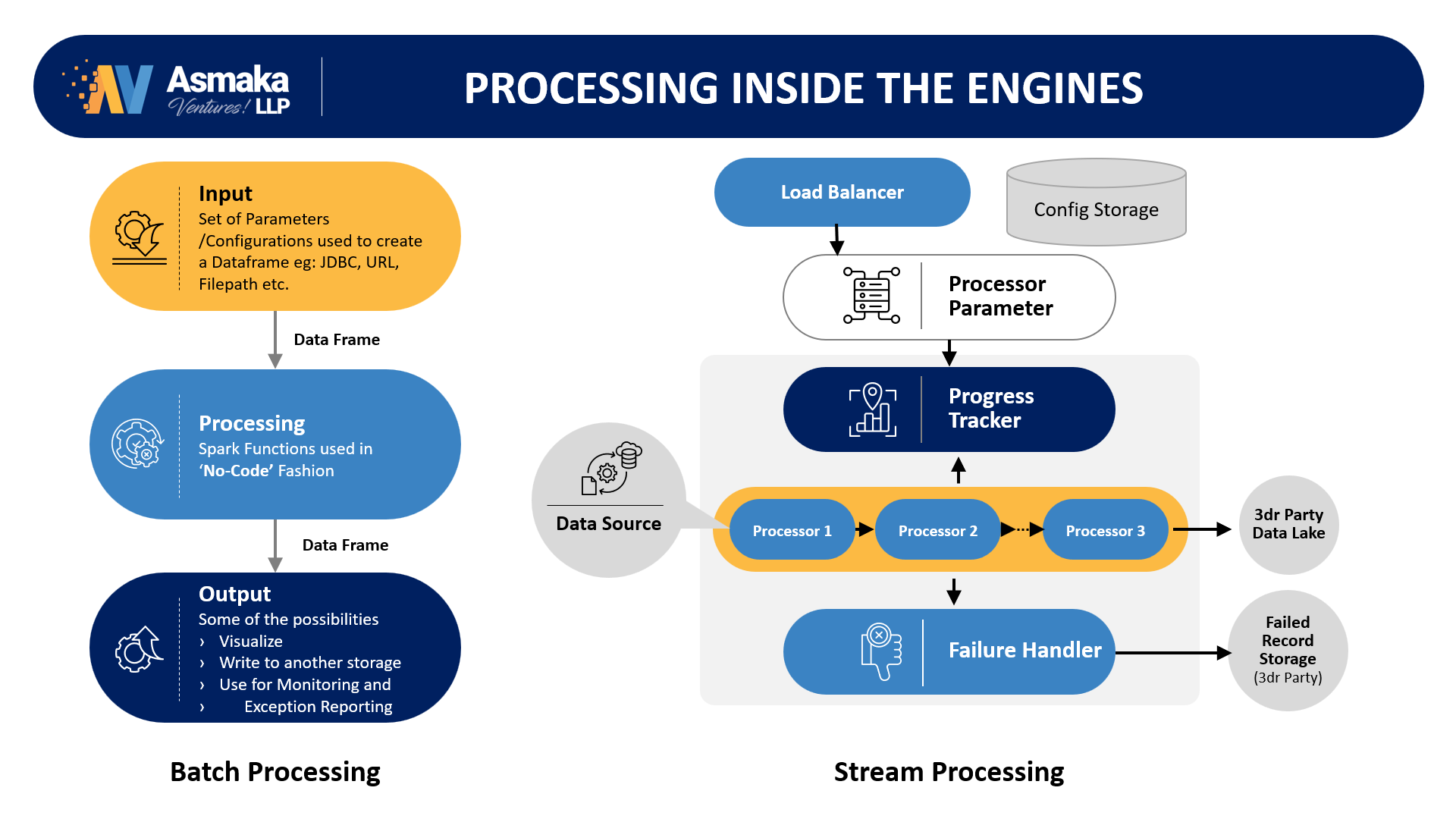
As we bring an end-to-end Data Management platform story, this is a combination of several Data Engines, Distributed Processing Systems and Micro-Services. One Engine or combination of Multiple such Data Engines could serve your specific Use Cases around Data.
While this is Single IP story, we have given a view of major architectural blocks (Engines & Processing systems) here